Artificial Intelligence in d.velop Software
AI Use Casesfor Businesses and Organisations
The d.velop pilot: Build your own AI assistants
The d.velop pilot automatically recognises documents and their contents, generates summaries within seconds, and answers complex questions directly in the chat – all in natural, conversational language. Relevant knowledge from across the organisation is securely provided, enabling users to instantly access information such as contract durations or concise content overviews – without time-consuming research, conveniently via their own chat widget.

AI-powered document processing
Intelligent Document Processing (IDP) is a technology that automatically captures, transforms and processes data and documents. Using Artificial Intelligence (AI), Machine Learning (ML) and Natural Language Processing (NLP), specific information can be extracted and analysed from various types of documents. This enables the entire document lifecycle within businesses and organisations to be digitally and automatically supported.

AI-driven process automation combined with the d.velop process studio
Experience seamless integration of cutting-edge AI capabilities directly within the d.velop process studio. With our new feature, you can design and optimise recurring processes more efficiently. Effortlessly delegate tasks to AI using simple prompts, relieving your employees of tedious routine work and freeing up time for value-adding activities. Harness the power of artificial intelligence to make your workflows smarter and more productive.

d.velop pilot
Quickly and easily create your own AI assistants using your organisation’s knowledge
Every organisation holds vast amounts of valuable information in documents and archives. Yet this knowledge often remains untapped – due to a lack of technical capabilities and expertise needed to unlock it and make it usable in employees’ daily work. d.velop makes this possible with the d.velop pilot.
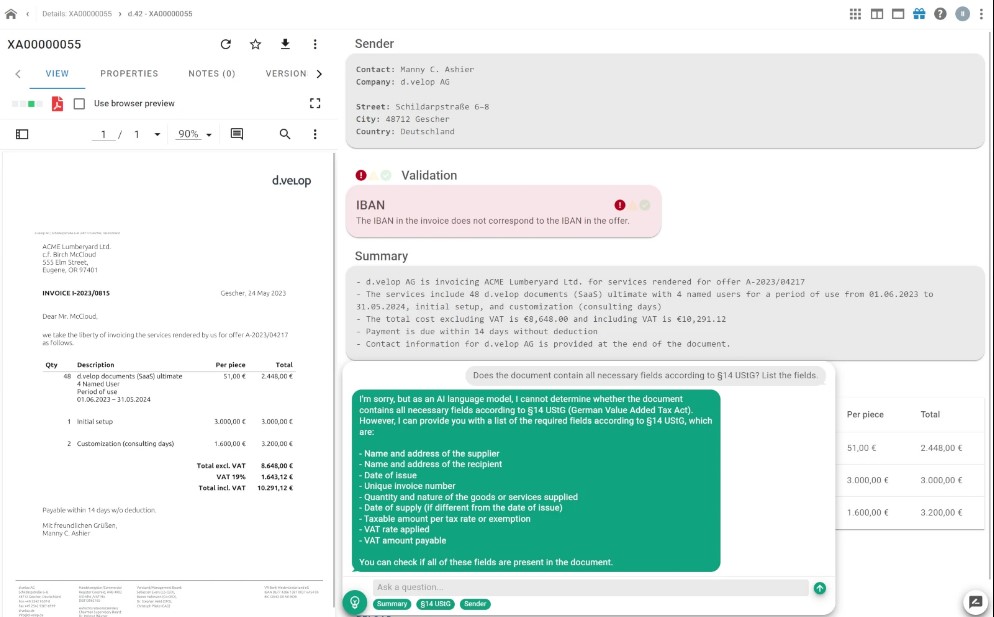
- Smart importing: Document types and properties can be automatically identified and clearly displayed in the index. Results from the AI are highlighted and can be output in seconds.
- Smart context: Contextual information is automatically generated for each document – for example, sender information or short summaries.
- Smart chat: The chat function allows you to ask questions about the document or enter information. Summaries of texts, responses relating to queries about contractual deadlines, and other information are made available in real time.
d.velop documents
AI-Assisted Document Processing
In many companies and organisations, capturing and digitising documents is often still a manual process that takes a lot of time and isn’t fun. AI technologies provide the answer.
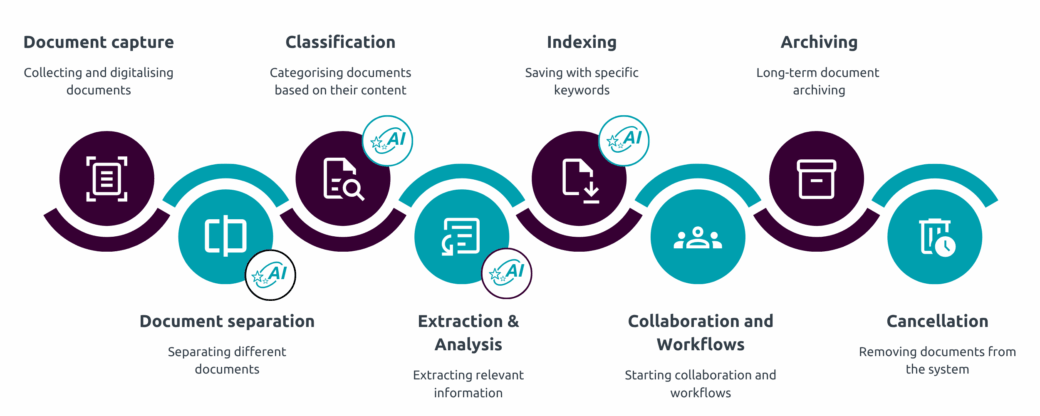
Split Documents
- AI-based document separation: Large volumes of scanned documents are automatically separated in seconds.
- Text and image analysis: Document identification relies on text and image data.
- You stay in control: All suggestions can be easily overridden by the user.

Identify and Classify Documents
- Reliable identification of documents types, such as invoices, reminders, and delivery notes with AI.
- Workflows based on document type: Automatic classification in digital repositories or automated post distribution.
Extract Data from Documents
- Automatic pattern recognition in text files with extraction of relevant information.
- Innovative Natural Language Processing (NLP) technologies allow options such as automatic reading of invoice data such as the invoice number, date, or amount when processing invoices – even without rule sets or keywords.

Intelligent Document Processing
Experience AI-Powered Document Processing

All reports can be fed into the DMS, allowing users to ask content-related questions directly to the AI – rather than just filtering or sorting the data. There's no need to process or review the reports manually in order to make use of them.


Assigning incoming documents to a creditor? At Schalke, this task is no longer handled solely by the accounting team – it's now supported by an AI-powered DMS. As part of the invoice processing workflow, the system automatically suggests account assignments based on the document content.

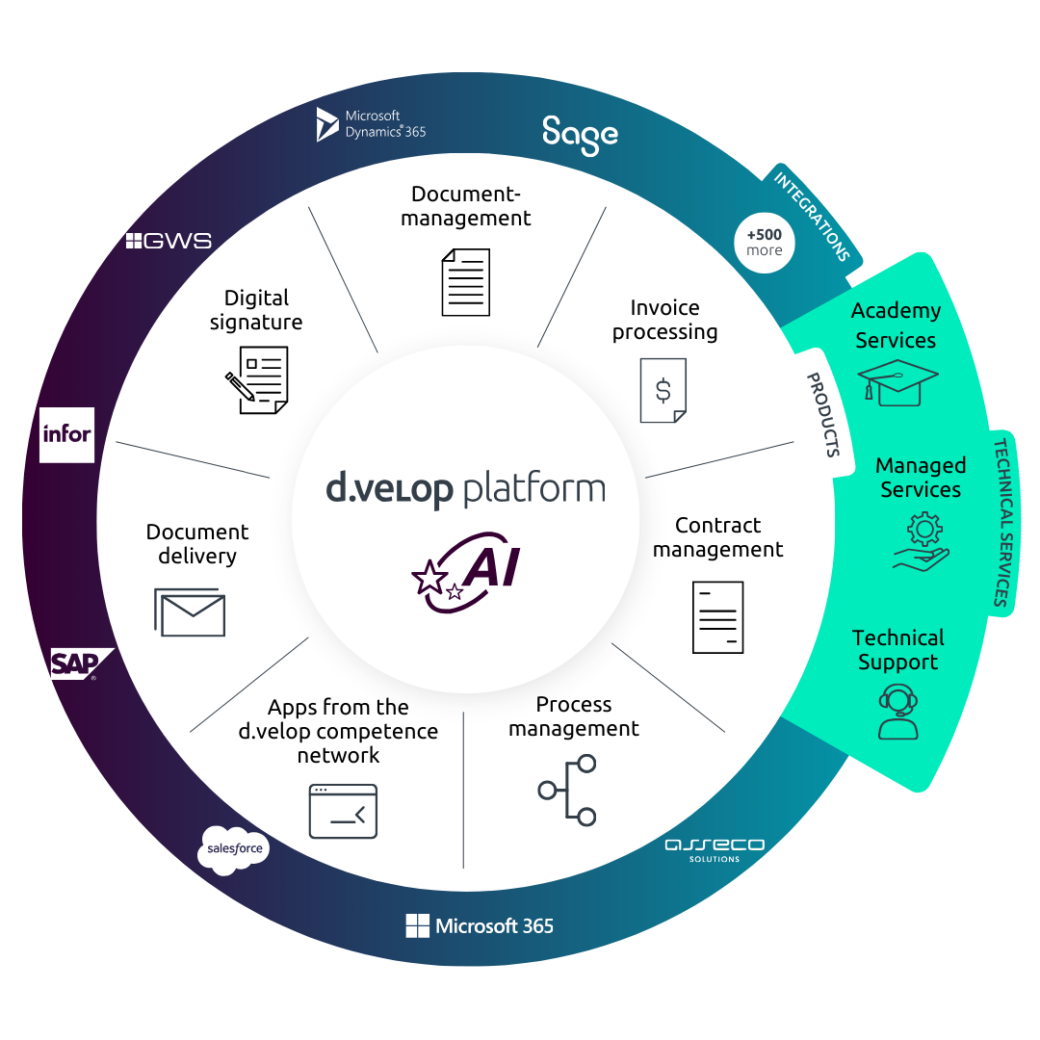
AI meets platform economy
Just like the entire d.velop platform, we rely on collaboration. The d.velop software is continuously enhanced by a growing number of specialised offerings from AI companies such as OpenAI, Parashift, ambeRoad and many others. Through these AI partnerships, d.velop customers gain access to the full spectrum of cutting-edge AI innovations.
You can be confident that industry-specific solutions are also available via the d.velop platform. Whether it’s generative AI models, highly specialised approaches for extracting information, or the combination of diverse technologies – the d.velop platform doesn’t tie you to a single provider. Instead, it offers a wide range of options to choose from.
And just like d.velop itself, many app builders on the d.velop platform are already integrating AI into their solutions as a matter of course – to deliver the best possible software experience.
Insights and Resources on AI
Interested in a Deep Dive?
Discover how AI is transforming document management and business workflows – with news and detailed information right here.
Zentis uses d.velop to summarise documents with the help of AI

Read the blog article to discover how Zentis relies on d.velop and leverages artificial intelligence to summarise documents – in an innovative and efficient way.
Process Automation with AI: Faster. Fewer Errors. Smarter Decisions.

Businesses around the world are under immense pressure to make their processes more efficient, scalable, and error-free. Intelligent process automation – the combination of artificial intelligence (AI) and modern workflow automation – holds enormous potential for all businesses.
d.velop UKI Establishes Strategic Partnership with Imagefast

We are excited to collaborate with Imagefast to deliver smarter, secure information management and workflow solutions for their customers.
d.velop UKI Establishes Strategic Partnership with Cognition24

C24’s client-first approach and technical depth are a perfect complement to d.velop’s powerful ECM and process automation platform. We’re excited to shape the future of intelligent digital transformation together.
FAQ
Frequently Asked Questions about AI
The term AI encompasses a few different things.
Firstly, there are two main types of AI, defined by their scope:
1) Narrow (weak) AI: The AI does not have a comprehensive understanding and exists solely to perform one task.
2) General (strong) AI: The AI has comprehensive understanding and a consciousness, just like a human being. At present, this remains a theoretical form.
Now let’s look at three key subsets or applications of AI:
3) Machine Learning: A computer uses algorithms to learn from data and experience, enabling it to improve its performance on a specific task.
4) Natural Language Processing: The computer can understand and work with human language, e.g., in the form of chatbots.
5) Robots and autonomous systems: These use AI-based technology to autonomously perform tasks and make decisions, without constant human supervision. Autonomous robots are used in various fields, for example, car manufacturing, agriculture, or exploration.
A Large Language Model (LLM) is a large, pre-trained language model based on neural networks with transformer architecture and deep learning algorithms. The pre-training is done on very large amounts of text and fine-tuned for specific tasks.
Large Language Models (LLMs) “understand”, process, and generate natural language and can be used for many tasks, such as responding to questions, or summarising, supplementing, translating, or generating texts. LLMs can even handle complex texts, questions, or instructions, and generate grammatically and orthographically correct, coherent written results. [Admittedly, the text you’re reading right now was written and then translated by skilled human beings.]
Natural Language Processing (NLP) is a subfield within artificial intelligence (AI). The aim of NLP is to enable computers to understand human (or “natural”) language. Conversely, it could also enable people without programming skills to interact with intelligent machines. Important aspects within NLP include text processing, speech recognition, word and semantic similarity, sentiment analysis, language translation and generation, and question-answering systems. NLP-based AI engines can often engage in natural-like dialogue with humans, for example, through advanced chatbots or voice assistants.
Machine learning is a rapidly developing subfield within artificial intelligence. It is used and researched in NLP-related areas such as speech recognition or translation, as well as a wide range of other areas such as autonomous vehicles, medical diagnosis, game development, or manufacturing. The aim of ML is to enable computers to learn through experience and resolve certain challenges or complete certain tasks better and better over time. At the root of ML lies a form of data analysis, pattern recognition, and decision-making, allowing the AI model to perform tasks or make predictions.
In document recognition, the AI uses machine learning techniques to learn from example datasets: For example: Business documents are translated into an abstract form. This is then used to create a mathematical model of the documents. This in turn can be used to make statements about the documents. The learning process involves reviewing many thousands of examples in a dataset for which the desired answer is already known. Each time a new example is presented, the AI model makes a prediction. If this is not correct, the model is adjusted to reduce future errors. The AI model learns from its mistakes.
Contact & Consultation
Get to know the AI-powered d.velop software
Request your personalised live demo of the d.velop software in just a few clicks. Experience the software live and ask your questions directly.
Simply fill out the form – we’ll get in touch with you shortly.